Topological sorts
Detecting and finding cycles in directed graphs are common problems in graph theory. A while back I was looking for an algorithm to detect whether a graph had a cycle or not, and it turns out there are a lot of different ways to approach this. Ultimately, the best method to use will probably depend on why you’re looking for cycles, and what you want to do with them (or their absence).
In my case, I was looking for something that I later learned is called a topological sort. A topological sort is an ordering of the vertices in a graph, such that for any directed edge from vertex \(u\) to \(v\), \(u\) comes before \(v\) in the ordering. Obviously, there may be many such orderings (consider the orderings possible on two vertices with no path between them). If the graph has one or more cycles, however, no such ordering exists. If it did, every vertex in the cycle would necessarily come before all the other vertices in the cycle, which would be a contradiction.
Being able to find a valid topological sort is therefore equivalent to determining whether or not a directed graph has a cycle. It’s also pretty intuitive that a process looking for cycles might keep a topological sort of visited vertices during its search.
A quick look on wikipedia reveals two algorithms to find a topological sort, both with linear running times. One is a slightly modified depth first search, while the other, Kahn’s algorithm, is new to me. Which one is faster in practice? Let’s find out.
We’ll make some simple graph and node (representing vertices) classes in Java for our benchmarks, using the adjacency list representation.
class Graph {
Node[] nodes;
}
class Node {
Node[] children;
}
Depth first search
Regular DFS works by marking each node as visited during the search, and exploring paths as far as possible before backtracking. While this approach is perfectly capable of detecting cycles, it will also give false positives. Consider the following two graphs.
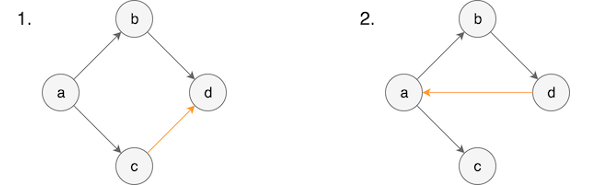
The first graph has a loop, but it is not a cycle. There is no path that begins and ends at a single node. The second graph has an obvious cycle, which can be characterized by the path \(p = a \to b \to d \to a\). Applying DFS to the second graph, the algorithm will follow \(p\). When it gets to \(a\) the second time, it will discover that it has already been visited, and correctly conclude that a cycle exists. No matter where DFS begins, it will detect the cycle.
What happens when DFS searches the first graph? Suppose we follow the first part of \(p\) again, visiting \(a\), \(b\), and then \(d\). At this point, there are no more outgoing edges, so \(d\) is popped from the search stack, leaving us at \(b\). No more outgoing edges are available here either, so \(b\) is popped and we are back at \(a\). The algorithm then visits \(c\), and discovers an edge to \(d\), which is marked visited. It may then incorrectly conclude that there exists a cycle.
What’s the difference between these two cases, and how can we modify DFS to only find actual cycles? In the search on the first graph, we visited \(d\) for the second time only after it had been popped off the search stack. In the search of the second graph, you will notice that \(a\) was still in the search stack when the edge \(d \to a\) was traversed. This will be the case independent of where DFS begins. Making this distinction will identify cycles every time.
In graph theory terms, \(d \to a\) is called a back edge, since \(a\) has already been visited, and is an ancestor of \(d\). For the first graph, \(c \to d\) is called a cross edge since \(d\) has already been visited, but it is neither an ancestor or descendent of \(c\). Other possibilities are forward edges (the node being visited for the second time is a descendent of the first node) and a tree edge (the node has not yet been visited). Only a back edge indicates the presence of a cycle. Note that this terminology only applies in the context of a specific search, i.e. starting at \(a\). If DFS were to start elsewhere, the edges may receive different terms.
Let’s implement our modified DFS. We will need to extend the Node class to include two boolean flags: visited, and inStack.
List<Node> topologicalSortDFS(Graph g) throws CyclicGraphException {
LinkedList<Node> sortedNodes = new LinkedList<Node>();
for (Node n : g.nodes) {
if (!n.visited) {
visit(sortedNotes, n);
}
}
return sortedNodes;
}
void visit(LinkedList<Node> sortedNodes, Node n) throws CyclicGraphException {
if (n.inStack) throw new CyclicGraphException();
n.inStack = true;
for (Node child : n.children) {
if (!child.visited) {
visit(sortedNodes, child);
}
}
n.visited = true;
n.inStack = false;
sortedNodes.addFirst(n);
}
Kahn’s algorithm
While the modified DFS builds the topological sort starting with the nodes that must be ordered last, Kahn’s algorithm visits nodes in the same order as the eventual sort.
The algorithm starts with a set of nodes that have no incoming edges. These nodes can be placed at the beginning of the sorted list without any issues. Once a node is added to the list, the algorithm removes all edges beginning from this node, potentially creating new nodes that now have no incoming edges. It keeps placing nodes in the sorted list until all nodes have been placed in the list, or there are no more nodes without any incoming edges. The latter case indicates a cycle, since a graph where every node has at least one incoming edge necessarily contains a cycle.
Our current graph structure does not easily allow us to find nodes without incoming edges. In the interest of comparing the two algorithms fairly, we will assume this information is available a priori since it depends on the way that the graph is stored. We will therefore assume the Node class instead has a hashset of parent nodes. The use of a hashset will allow the algorithm to efficiently remove edges.
class Node {
Node[] children;
Set<Node> parents;
}
Let’s implement the algorithm, using the new Node class.
List<Node> topologicalSortKahn(Graph g) throws CyclicGraphException {
List<Node> sortedNodes = new LinkedList<Node>();
Queue<Node> freeNodes = getFreeNodes(g);
while (freeNodes.size() > 0) {
Node n = freeNodes.remove();
sortedNodes.add(n);
removeEdges(freeNodes, n);
}
if (sortedNodes.size() != g.nodes.length) throw new CyclicGraphException();
return sortedNodes;
}
void removeEdges(Queue<Node> freeNodes, Node parent) {
for (Node n : parent.children) {
n.parents.remove(parent);
if (n.parents.isEmpty()) {
freeNodes.add(n);
}
}
}
Queue<Node> getFreeNodes(Graph g) {
Queue<Node> freeNodes = new LinkedList<Node>();
for (Node n : g.nodes) {
if (n.parents.isEmpty()) {
freeNodes.add(n);
}
}
return freeNodes;
}
Ad hoc benchmarks
To perform an ad hoc (read, not very scientific) benchmark of the two algorithms, I performed the following tests with the following parameters:
- Nodes: 2000
- Graphs generated: 100
- Number of test runs per graph: 100
The graphs were randomly generated using a probability \(p\) of creating an edge between two nodes (bearing in mind that for acyclic graphs, only half of all possible edges are considered). All times are in microseconds.
The JVM was “warmed up” with a full test run of 100 graphs. I randomly interleaved the test runs on the two different algorithms. Hopefully, this has removed a sufficient amount of bias from the results. I also removed the expensive exceptions from the implementations, opting instead for a null return value when a cycle was detected.
Topological sort results
To test the topological sort, I needed acyclic graphs. Fortunately, there’s an easy way to generate these. If we loop through the nodes and only generate random edges from a node to nodes after itself, we will end up with an acyclic graph. Sound familiar? By looping through the nodes in this manner, we are imposing a valid topological order, guaranteeing an acyclic graph.
To randomize the topological order relative to the way the nodes are stored in the Graph structure and the adjacency lists (which are consistent in their ordering, something I imagine would be common in real world applications), I generated a random topological ordering for each graph using the Fisher-Yates shuffle.
| \(p\) | DFS | Kahn | ratio |
|---|---|---|---|
| 0.003 | 80.2 | 238.1 | 0.337 |
| 0.01 | 96.9 | 624.9 | 0.155 |
| 0.03 | 205.9 | 2254.2 | 0.091 |
| 0.1 | 527.9 | 12224.6 | 0.043 |
| 0.3 | 1537.3 | 103981.2 | 0.015 |
The modified DFS is the clear winner, doing even better relative to Kahn’s algorithm as the graphs become more dense.
Common cycle detection results
Even for very sparse graphs (small \(p\)), generating completely random graphs results in cyclic graphs with overwhelming probability. As such, we can be certain that these graphs contain many cycles.
| \(p\) | DFS | Kahn | ratio |
|---|---|---|---|
| 0.003 | 0.9 | 24.3 | 0.036 |
| 0.01 | 0.7 | 31.5 | 0.022 |
| 0.03 | 0.9 | 41.4 | 0.022 |
| 0.1 | 0.8 | 50.0 | 0.018 |
| 0.3 | 1.0 | 54.7 | 0.019 |
This is reflected in the results, with both algorithms finding cycles and exiting very quickly. Remarkably, DFS appears to be able to do this approximately 50 times faster than Kahn’s algorithm for graphs of this size. Given the scale of less than a microsecond, however, one might wonder whether the timing was accurate enough to conclude this with certainty.
In any case, it is unlikely that these algorithms would be applied to cycle-heavy graphs. So let’s try a different test.
Rare cycle detection results
To generate random graphs with few cycles, I generated acyclic graphs using the approach above. Then I added a few random edges, hopefully introducing a cycle somewhere. I found 4 such random edges to be sufficient in general, except for very small \(p\). \(T\) represents the number of cyclic graphs that the following data is based on, out of 100 total graphs (the rest remained acyclic).
| \(p\) | \(T\) | DFS | Kahn | ratio |
|---|---|---|---|---|
| 0.003 | 10 | 1.5 | 23.0 | 0.064 |
| 0.01 | 71 | 13.6 | 310.3 | 0.043 |
| 0.03 | 93 | 32.6 | 1042.3 | 0.031 |
| 0.1 | 93 | 54.4 | 5121.7 | 0.011 |
| 0.3 | 94 | 112.5 | 40729.0 | 0.003 |
DFS remains much faster than its counterpart!
Conclusion
Why is DFS significantly faster at generating topological sorts?
I think the answer lies in its simplicity. DFS runs using very basic graph structure. It only needs an adjacency list to work, which can be implemented as an array. Kahn’s algorithm requires the ability to find parent nodes and remove them in constant time. This naturally requires a more expensive data structure, with more expensive operations. This is reflected in its relatively poorer performance the more edges there are.
For cycle detection, the same applies. DFS stumbles on cycles randomly, while Kahn’s algorithm finds them in the order of where the nodes would lie in a topological sort. Since the ordering of the vertices was random, there shouldn’t be much of a difference.
In short, DFS is your algorithm of choice! It is remarkably simple and elegant.